I really like fog it seems… Here are some more pictures 🙂
Year: 2018
-
Visualizing focal lengths used in photos
I am currently in the process of (perhaps) buying a new camera. Currently I have a Sony A6000 with one standard zoom lens that has a focal length that goes from 18-50mm (or 24-75mm if you translate to 35mm sensors).
The cameras I’m looking at currently are full-format cameras, and the lenses for those cameras can get quite expensive – so I’m wondering if I can get away in the beginning just buying a fixed lens for the camera (cheaper).
The structured approach would of course be to analyze my photos taken with the zoom lens and see which focal length I use the most – since I want to get better at Python I decided that writing a Python script for this was the way forward. The script turned out to be quite short – the only dependency I didn’t already have installed was pillow.
The programming part
First we need to see if we can get the focal length easily, searching the spec for suitable EXIF information I found that 41989 is the key with the descriptive name “FocalLengthIn35mmFilm” – let’s try that!
import PIL.Image import matplotlib.pyplot as plt FocalLengthIn35mmFilm = 41989 img = PIL.Image.open("image.JPG") exif_data = img._getexif() print exif_data[FocalLengthIn35mmFilm]It seems to work for most of my images, lets loop through all images in the folder and try it out
import PIL.Image import matplotlib.pyplot as plt import glob, os for file in glob.glob("./**/*.JPG"): FocalLengthIn35mmFilm = 41989 img = PIL.Image.open("image.JPG") exif_data = img._getexif() print exif_data[FocalLengthIn35mmFilm]This appears to be working for most of my pictures – some images doesn’t contain any FocalLengthIn35mmFilm parameter so I’m skipping those images for now with a try/except and logging to stdout.
Instead of printing the sizes I need to add it to an array to visualize it with a histogram – check below for finished script.
Finished script
import glob, os import PIL.Image import matplotlib.pyplot as plt focal_length_35 = [] FocalLengthIn35mmFilm = 41989 # Go through all JPG-files in all folders for file in glob.glob("./**/*.JPG"): img = PIL.Image.open(file) exif_data = img._getexif() try: focal_length_35.append(int(exif_data[FocalLengthIn35mmFilm])) except: print "ERROR in file %s" % (file) # Show histogram plt.hist(focal_length_35) plt.show()Running the script above in a folder with some pictures gave me the following histogram
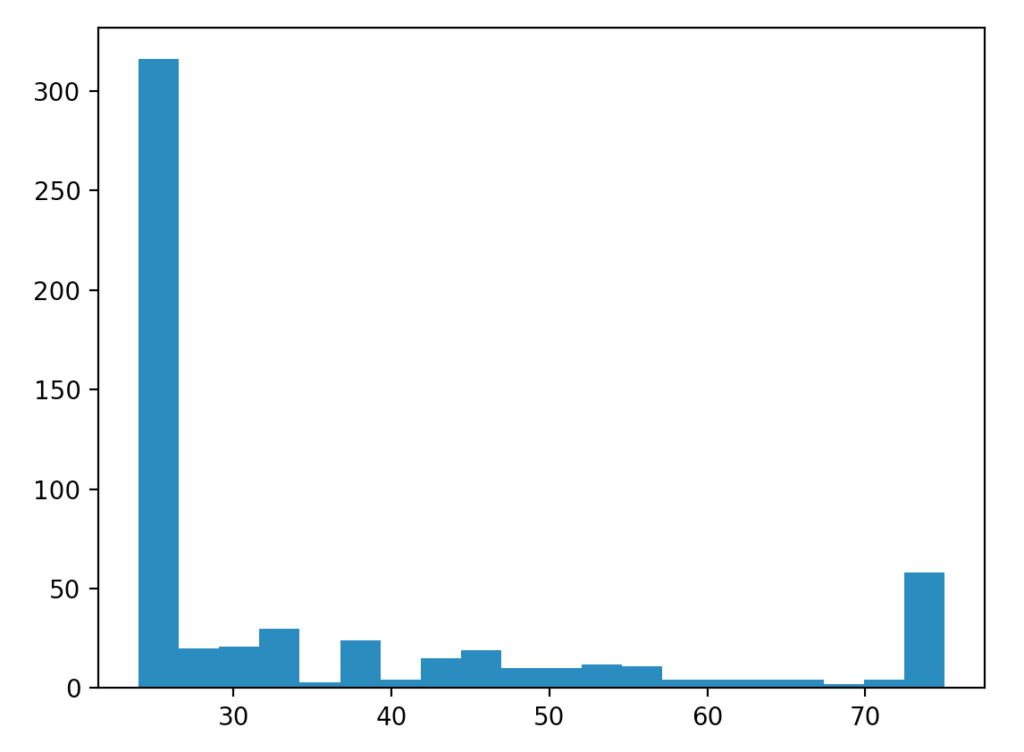
It seems that I’m a clear fan of focal length 24mm (at least for the folder I ran this on), something to think about at least. Now I probably need to go through all photos and separate the ones I like the most so I know which focal length I’m most happy with (the above script only gives me quantity, not the quality).
-

Pixel 2 vs A6000
A comment on my instagram sparked a long running debate in my head – is carrying a real camera worth it?
I’ve felt that the need for a “real” camera is disappearing more and more with smartphones really stepping up the game.
The picture in question 
Pixel 2
ƒ/1.8 1/17s 4.442mm ISO 1587
Sony A6000
ƒ/3,5 1/3s ISO 3200 -

Filenames with non-ascii letters
Let’s start off with a quick question!
Can you spot the difference between the two rows below?/images/räksmörgås.jpg /images/räksmörgås.jpgI couldn’t.
My browser however insisted that there was no “räksmörgås.jpg” on the webserver – a file that from my point of view clearly was there.
Since the error only occurred with filenames containing the letters å,ä & ö I at first suspected that there was an issue with mixing up UTF-8 and ISO-8859-1, however, this wasn’t the case.
My next course of action was to urlencode the requested filename and the filename from the server, and this is when I found something interesting!
ra%CC%88ksmo%CC%88rga%CC%8As r%C3%A4ksm%C3%B6rg%C3%A5sNow you see the difference, right?
The reason behind the difference is that there are multiple ways to represent the common Swedish letters å, ä and ö (and other non-ascii letters aswell – but for readabiltiy, let’s keep it short).
If we look at the char codes for three letters that were causing trouble in my case:
Letter | Mac OSX | Linux -------+-----------+------ å | 97 + 778 | 228 ä | 97 + 776 | 229 ö | 111 + 776 | 246Notice the pattern?
Mac uses ”a” (97) and ”o” (111) and then adds the circle (778) or the dots (776). Linux however has a diffrent char entirely.There are multiple standards for representing characters in unicode, the competing normal forms here are ”Canonical Decomposition” (NFD) and ”Canonical Composition” (NFC) – and I needed to convert between the two.
My solution
I had this error on a server where files had been stored on a Mac and then re-uploaded to a Linux server. I didn’t have shell access to the server so I fixed it by using the following PHP-code that looped through all affected files and updated their names:
<?php // Normalizes all filenames in folder foreach(glob("*", 2) as $file){ $after = Normalizer::normalize($file, Normalizer::FORM_C); if($file !== $after){ rename($file, $after); } }You could probably use iconv or similar tools to achieve the same thing easier if you’ve got shell-access (or php exec is enabled).
Fun fact: Räksmörgås is a commonly used Swedish word used for testing that the non-ascii ÅÄÖ is working correctly.